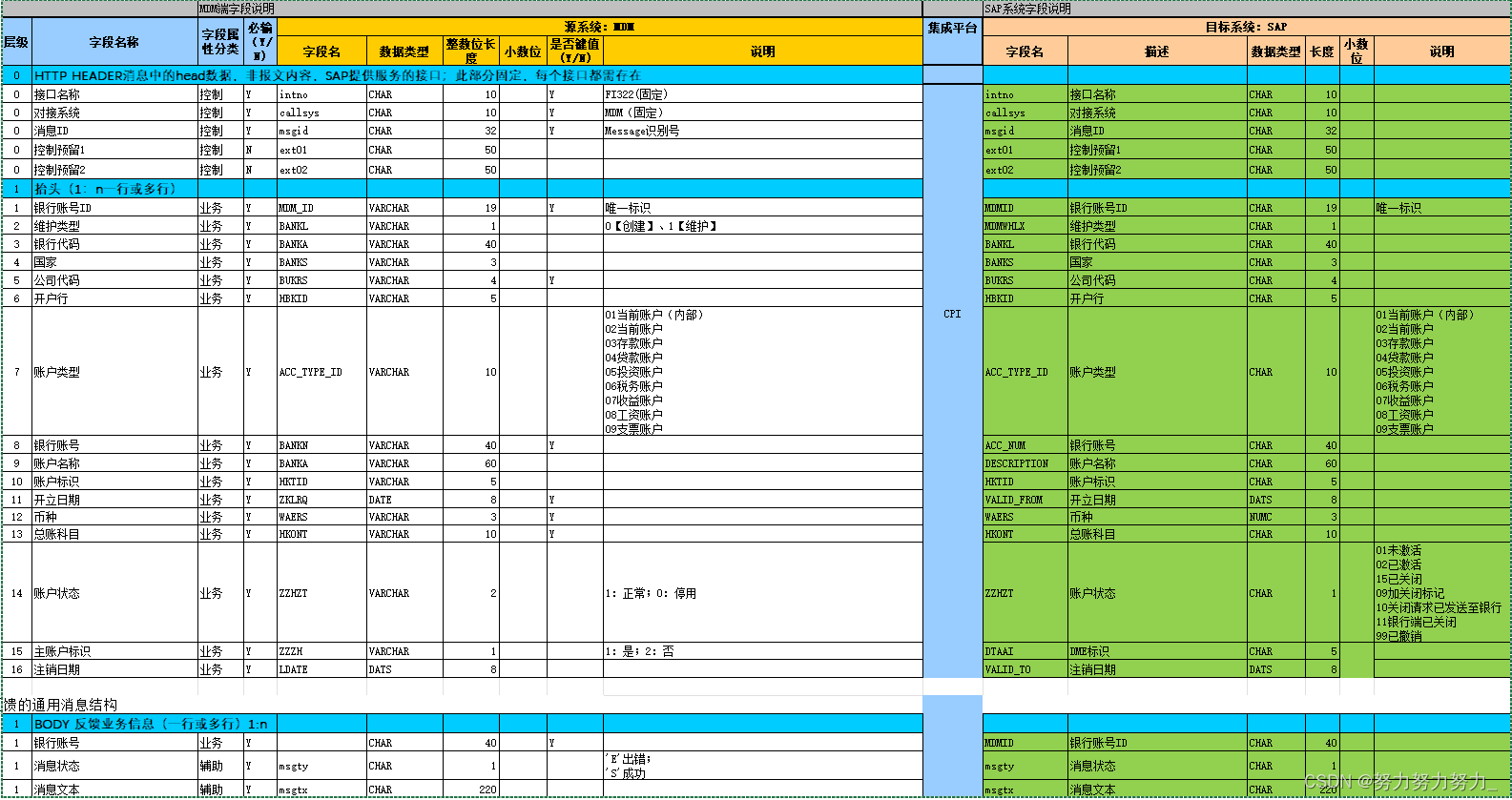
数据结构 —— 图的遍历
- BFS(广度遍历)
- 一道美团题
- DFS(深度遍历)
我们今天来看图的遍历,其实都是之前在二叉树中提过的方法,深度和广度遍历。
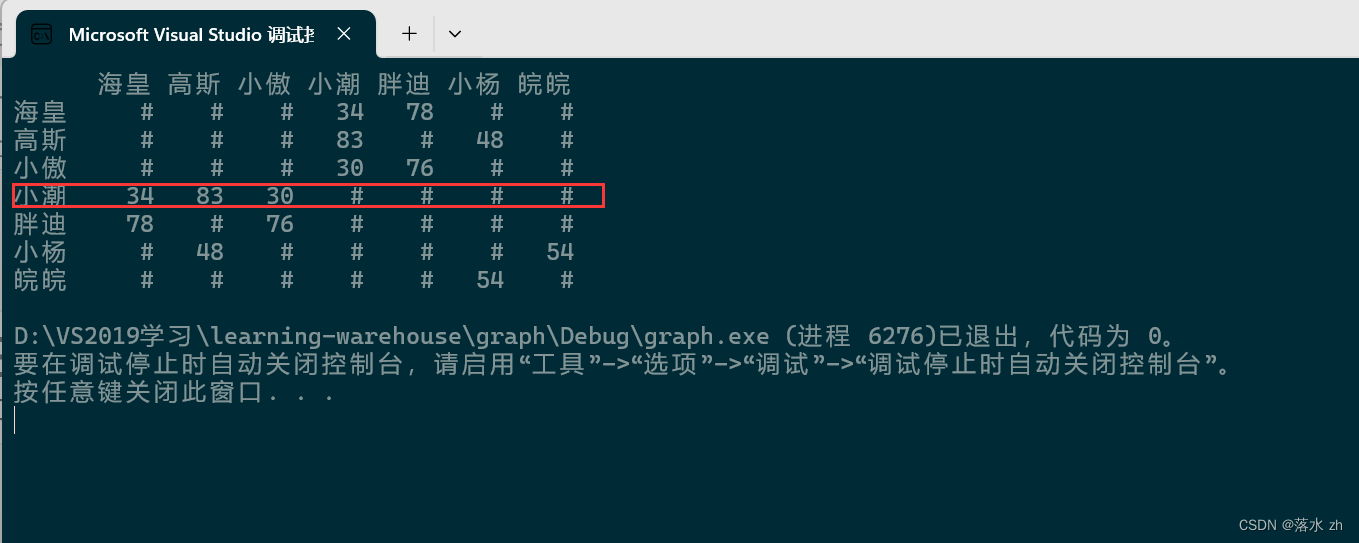
在这之前,我们先用一个邻接矩阵来表示一个图:
#pragma once
#include<iostream>
#include<vector>
#include<map>
using namespace std;
//图的模板化
namespace matrix
{
template<class V, class W, W MAX_W, bool Direction = false>
class Graph
{
public:
Graph(const V* vertex, size_t n)
{
//开辟空间
_vertex.reserve(n);
for (int i = 0; i < n; i++)
{
_vertex.push_back(vertex[i]);
_index[vertex[i]] = i;
}
//初始化矩阵
_matrix.resize(n);
for (auto& e : _matrix)
{
e.resize(n, MAX_W);
}
}
//寻找图中的点
size_t FindSrci(const V& vertex)
{
auto ret = _index.find(vertex);
if (ret != _index.end())
{
return ret->second;
}
else
{
throw invalid_argument("不存在的顶点");
return -1;
}
}
void _AddEdge(size_t srci, size_t desi, W w)
{
_matrix[srci][desi] = w;
if (Direction == false)
{
_matrix[desi][srci] = w;
}
}
//加边
void AddEdge(const V& srci, const V& desi, W w)
{
size_t srcIndex = FindSrci(srci);
size_t desIndex = FindSrci(desi);
_AddEdge(srcIndex, desIndex, w);
}
void Print()
{
//打印标题行
cout << " ";
for (int i = 0; i < _vertex.size(); i++)
{
cout << _vertex[i] << " ";
}
cout << endl;
//打印矩阵
for (int i = 0; i < _vertex.size(); i++)
{
cout << _vertex[i] << " ";
for (int j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] != MAX_W)
{
printf("%5d", _matrix[i][j]);
}
else
{
printf("%5c", '#');
}
}
cout << endl;
}
}
private:
//存放顶点
vector<V> _vertex;
//映射关系
map<V, size_t> _index;
//矩阵,图的表示
vector<vector<W>> _matrix;
};
void TestGraph()
{
Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();
}
void TestGraph2()
{
string a[] = {"海皇","高斯","小傲","小潮","胖迪","小杨","皖皖"};
Graph<string, int,INT_MAX, false> g1(a, sizeof(a)/sizeof(a[0]));
g1.AddEdge("小潮", "小傲", 30);
g1.AddEdge("小潮", "高斯", 83);
g1.AddEdge("小潮", "海皇", 34);
g1.AddEdge("胖迪", "海皇", 78);
g1.AddEdge("胖迪", "小傲", 76);
g1.AddEdge("小杨", "皖皖", 54);
g1.AddEdge("小杨", "高斯", 48);
g1.Print();
}
}
BFS(广度遍历)
广度优先遍历和之前二叉树的广度优先遍历一样,我们需要队列来辅助:
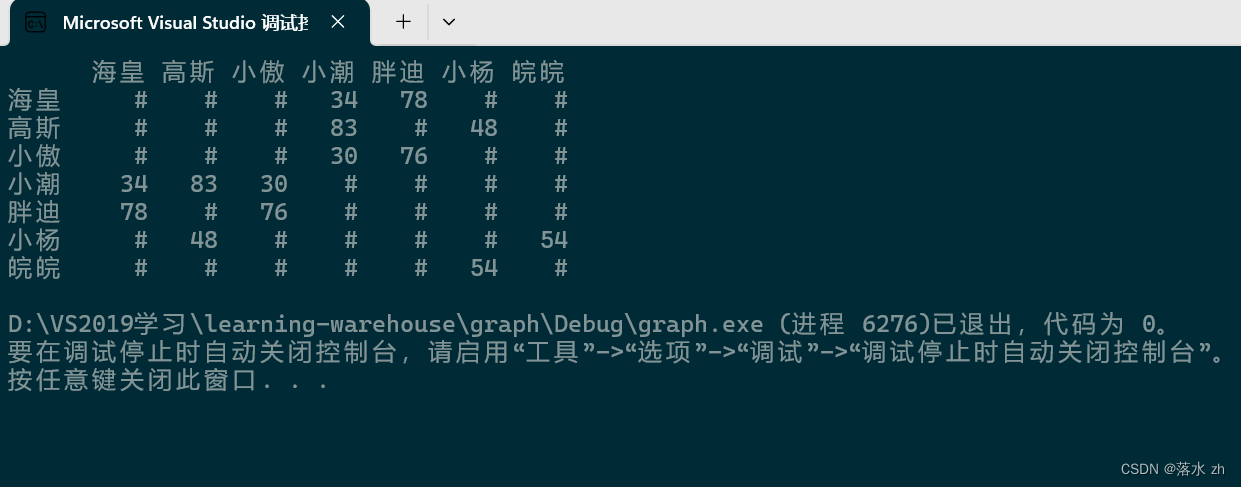
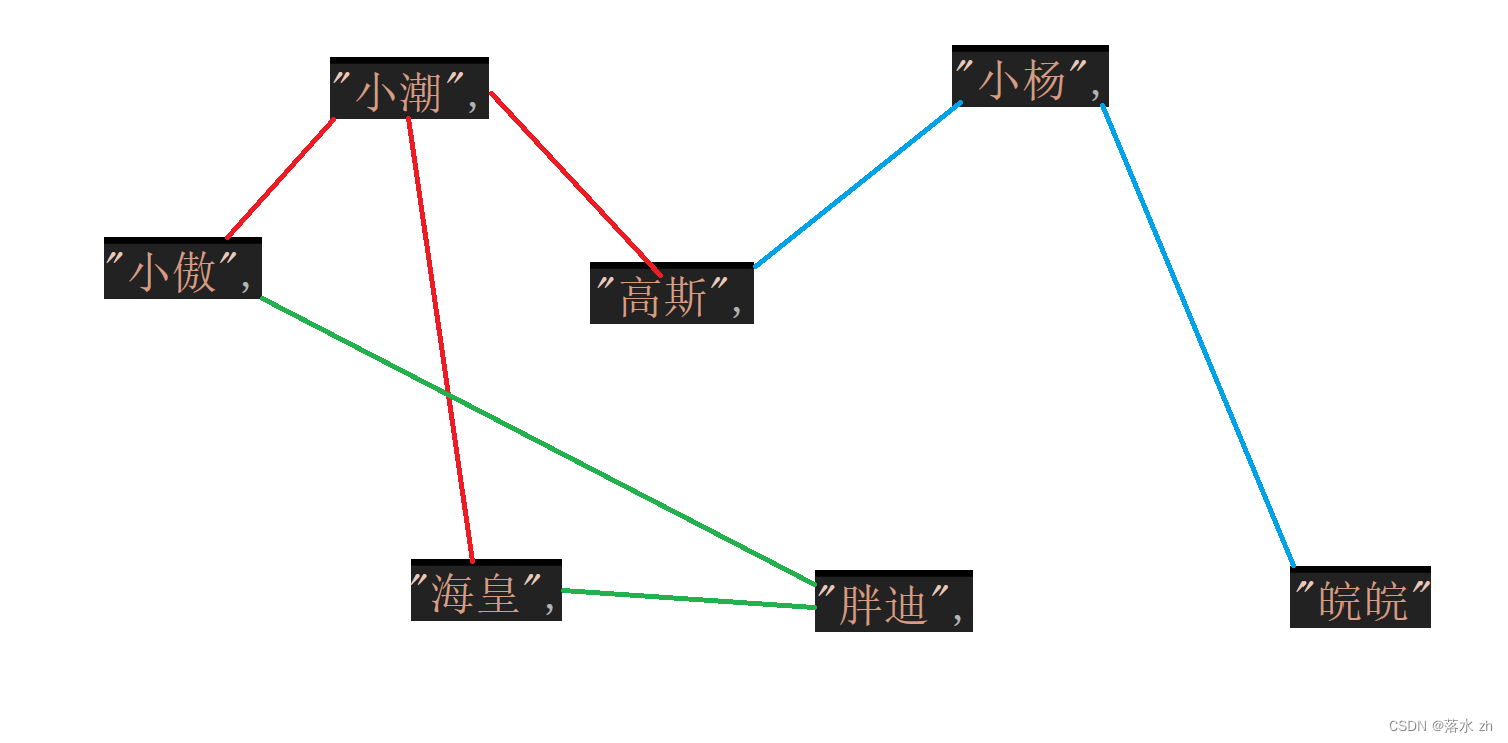
 我们逻辑上是这张图,但是我们实际遍历的时候,我们遍历的是一个矩阵(二维数组)
我们逻辑上是这张图,但是我们实际遍历的时候,我们遍历的是一个矩阵(二维数组)
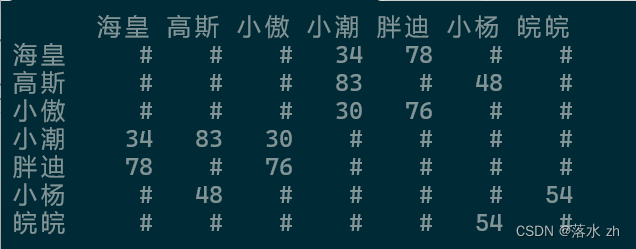 因为这个图是联通图,我们从任意一个顶点出发都可以遍历完所有顶点,假设我们从小潮开始:
因为这个图是联通图,我们从任意一个顶点出发都可以遍历完所有顶点,假设我们从小潮开始:
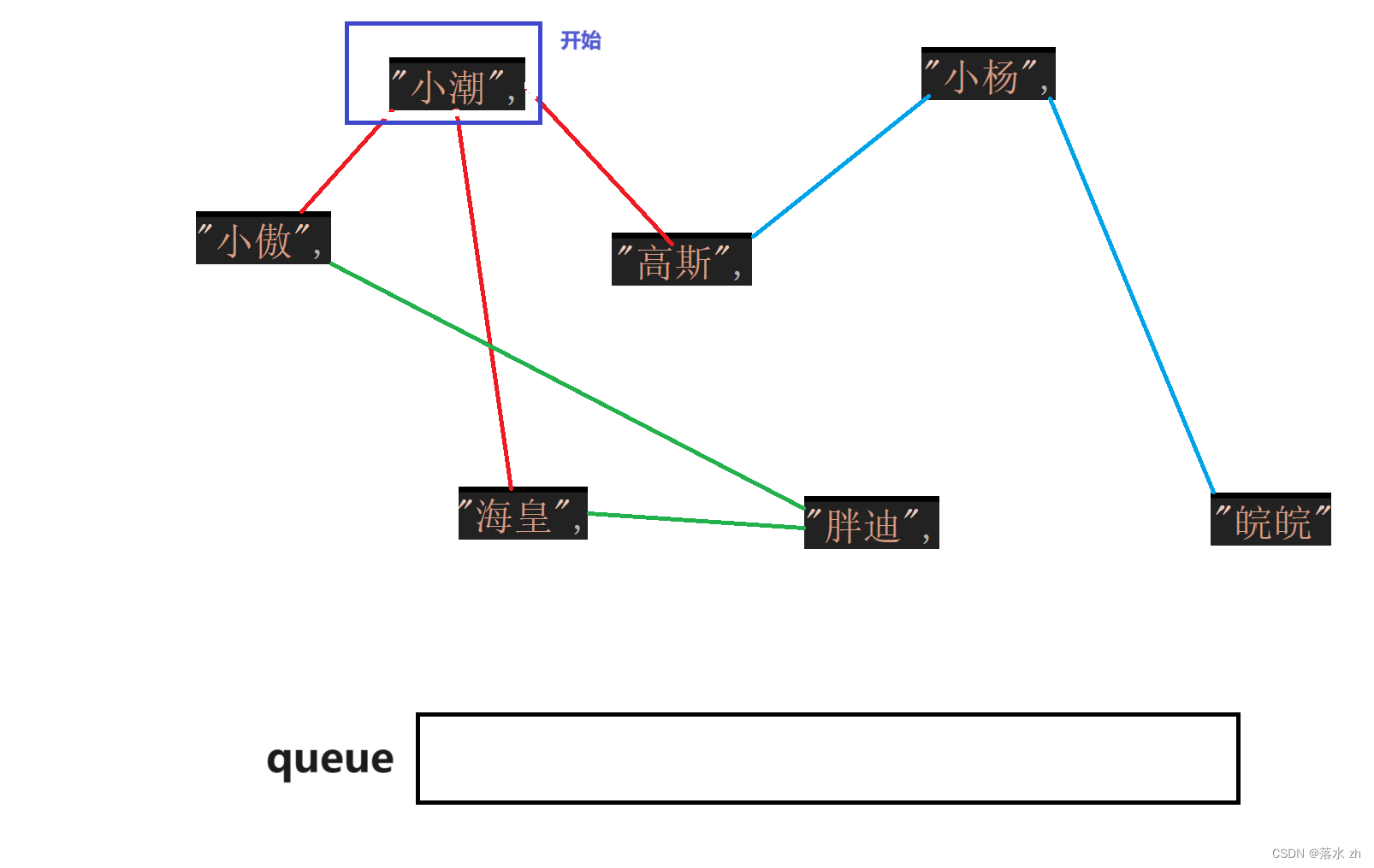 我们仿照二叉树那里的思路,把相连的节点入队列,把小傲,高斯,海皇入队列:
我们仿照二叉树那里的思路,把相连的节点入队列,把小傲,高斯,海皇入队列:
 在矩阵上的表现就是把小潮这一行,不为#的数值的结点入队列:
在矩阵上的表现就是把小潮这一行,不为#的数值的结点入队列:
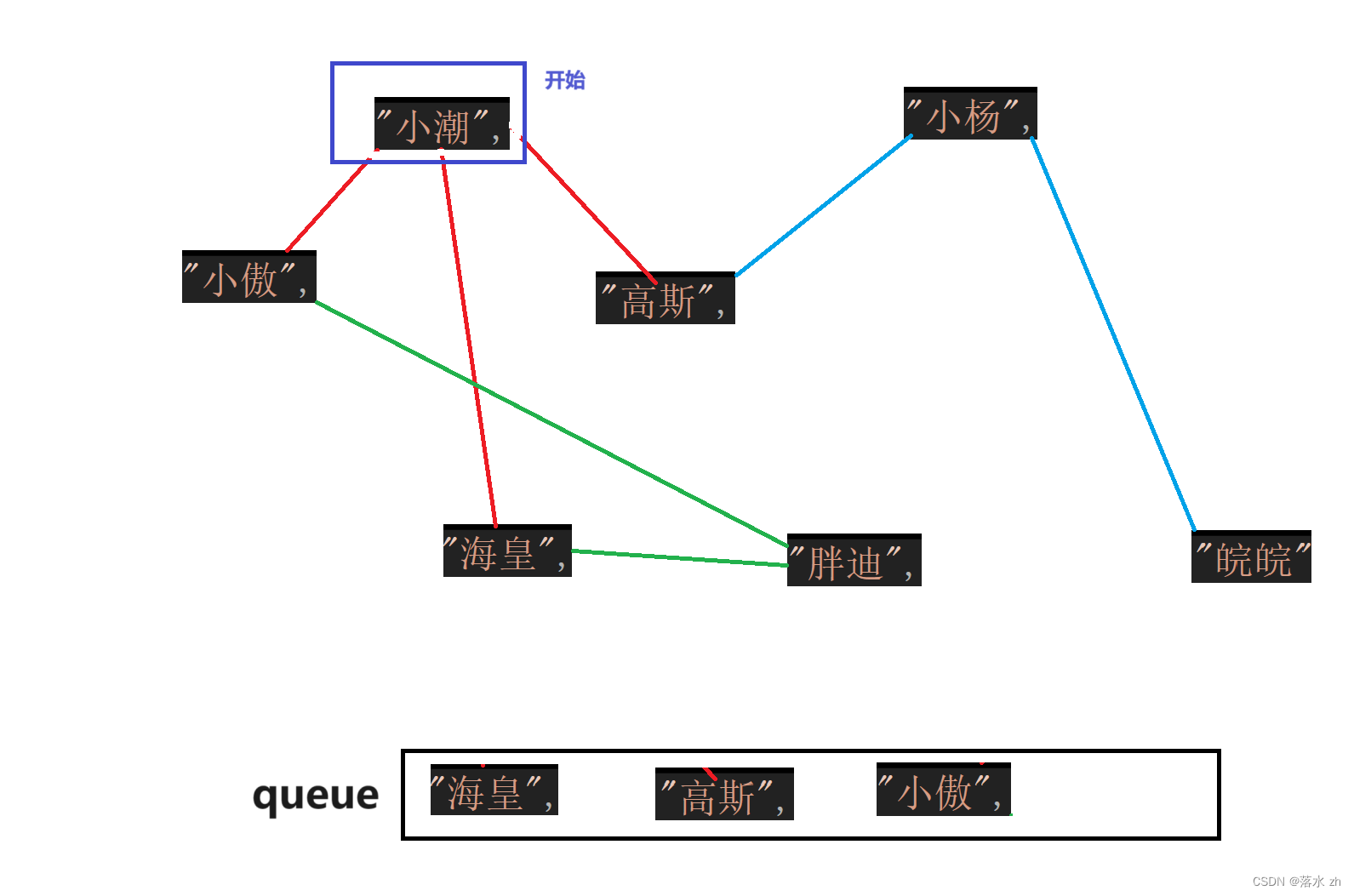
 好,现在有一个问题,假设我现在遍历到了海皇,海皇和小潮相连,按照上面的规则,我们应该把小潮入队列,但是我们一开始就是从小潮开始的,就会造成重复访问,这该则么办呢?
好,现在有一个问题,假设我现在遍历到了海皇,海皇和小潮相连,按照上面的规则,我们应该把小潮入队列,但是我们一开始就是从小潮开始的,就会造成重复访问,这该则么办呢?
所以在图这里,我们要引入一个数组,标记我们已经访问过的结点,标记过的结点在之后的访问过程中不再入队:

我们来实现一下:
void BFS(const V& vertex)
{
int vertexIndex = FindSrci(vertex);
//队列和标记数组
int n = _vertex.size();
queue<size_t> q;
vector<bool> visited(n, false);
//先入最先访问节点
q.push(vertexIndex);
//标记
visited[vertexIndex] = true;
while (!q.empty())
{
//出队
size_t front = q.front();
q.pop();
cout << _vertex[front] << " ";
//遍历该行
for (int i = 0; i < _vertex.size(); i++)
{
if (_matrix[front][i] != MAX_W)
{
if (visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
cout << endl;
}
}
一道美团题
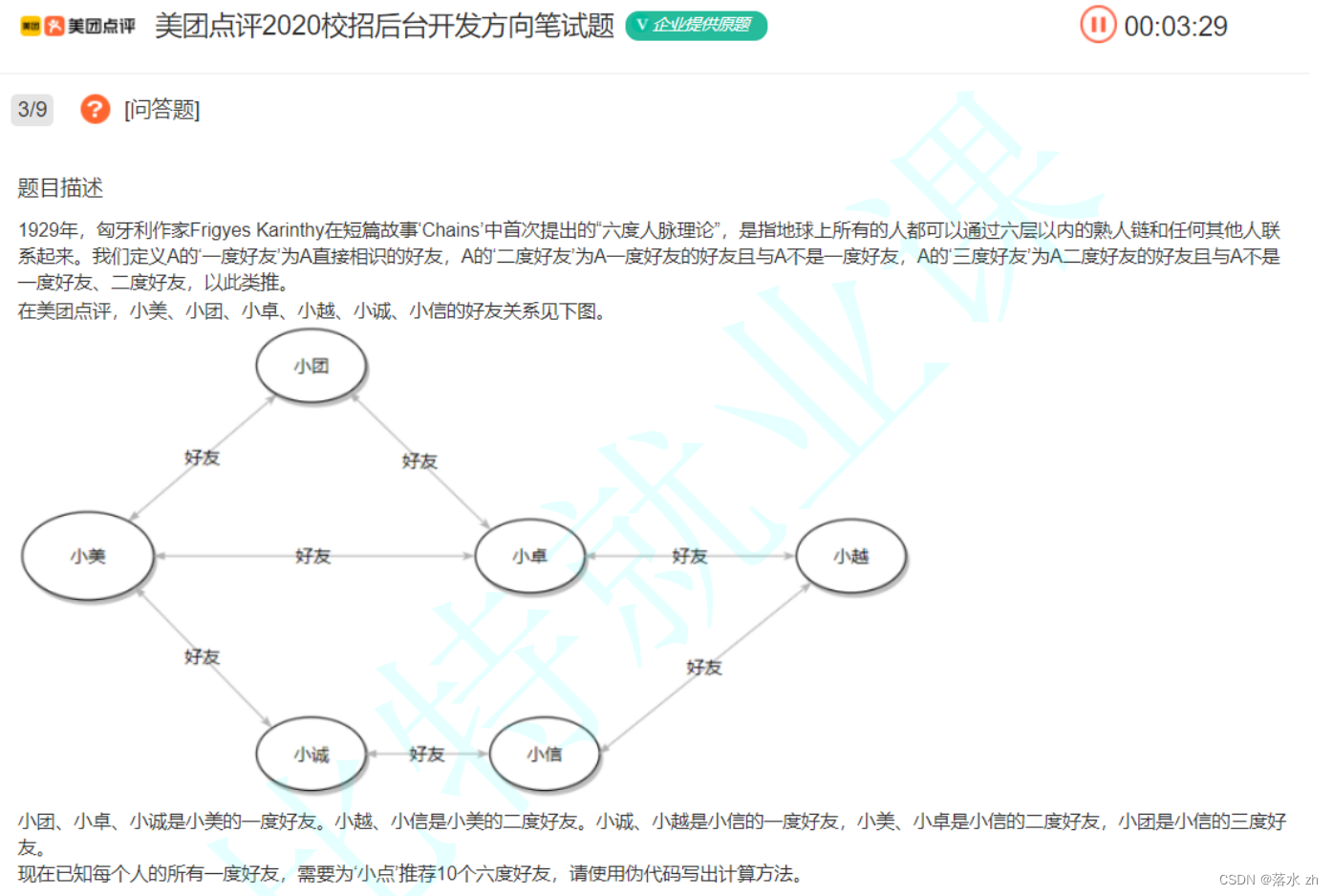 读了题之后,这里让我们计算几度好友,其实我们在BFS已经按照一度二度的顺序打印了,但是我们没有区分,我们区分一下就可以了
读了题之后,这里让我们计算几度好友,其实我们在BFS已经按照一度二度的顺序打印了,但是我们没有区分,我们区分一下就可以了
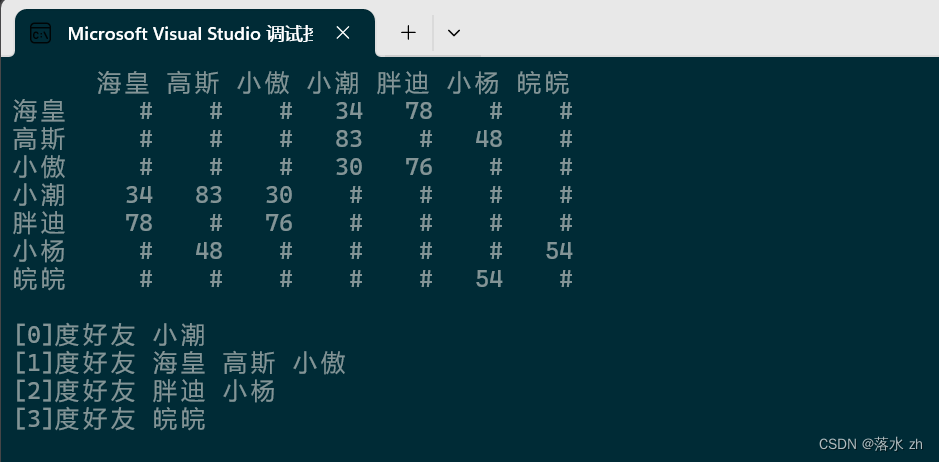
void BFS(const V& vertex)
{
// 获取目标顶点的索引
int vertexIndex = FindSrci(vertex);
// 初始化队列和标记数组
int n = _vertex.size();
queue<size_t> q; // 创建一个队列用于存储待访问的顶点
vector<bool> visited(n, false); // 创建一个布尔数组,用于标记顶点是否已被访问
// 将起始顶点添加到队列中,并标记为已访问
q.push(vertexIndex);
visited[vertexIndex] = true;
int levelSize = 1; // 初始化当前层级的顶点数量,初始时只有起始顶点
int degree = 0; // 初始化度数(即好友的层次)
// 当队列非空时,继续广度优先搜索
while (!q.empty())
{
// 输出当前度数的好友
cout << "[" << degree << "]" << "度好友 ";
// 对当前层级的所有顶点进行处理
for (int j = 0; j < levelSize; j++)
{
// 从队列中取出一个顶点
size_t front = q.front();
q.pop();
// 输出当前顶点的信息
cout << _vertex[front] << " ";
// 遍历与当前顶点相邻的所有顶点
for (int i = 0; i < _vertex.size(); i++)
{
// 如果存在一条边连接当前顶点和下一个顶点
if (_matrix[front][i] != MAX_W)
{
// 如果下一个顶点未被访问过
if (!visited[i])
{
// 将下一个顶点添加到队列中,以便后续访问
q.push(i);
// 标记下一个顶点为已访问
visited[i] = true;
}
}
}
}
// 更新下一层级的顶点数量
levelSize = q.size();
// 换行输出,准备进入下一度数的好友输出
cout << endl;
// 增加度数计数器
degree++;
}
// 最终换行,使输出更清晰
cout << endl;
}
DFS(深度遍历)
深度遍历是一条道走到黑:
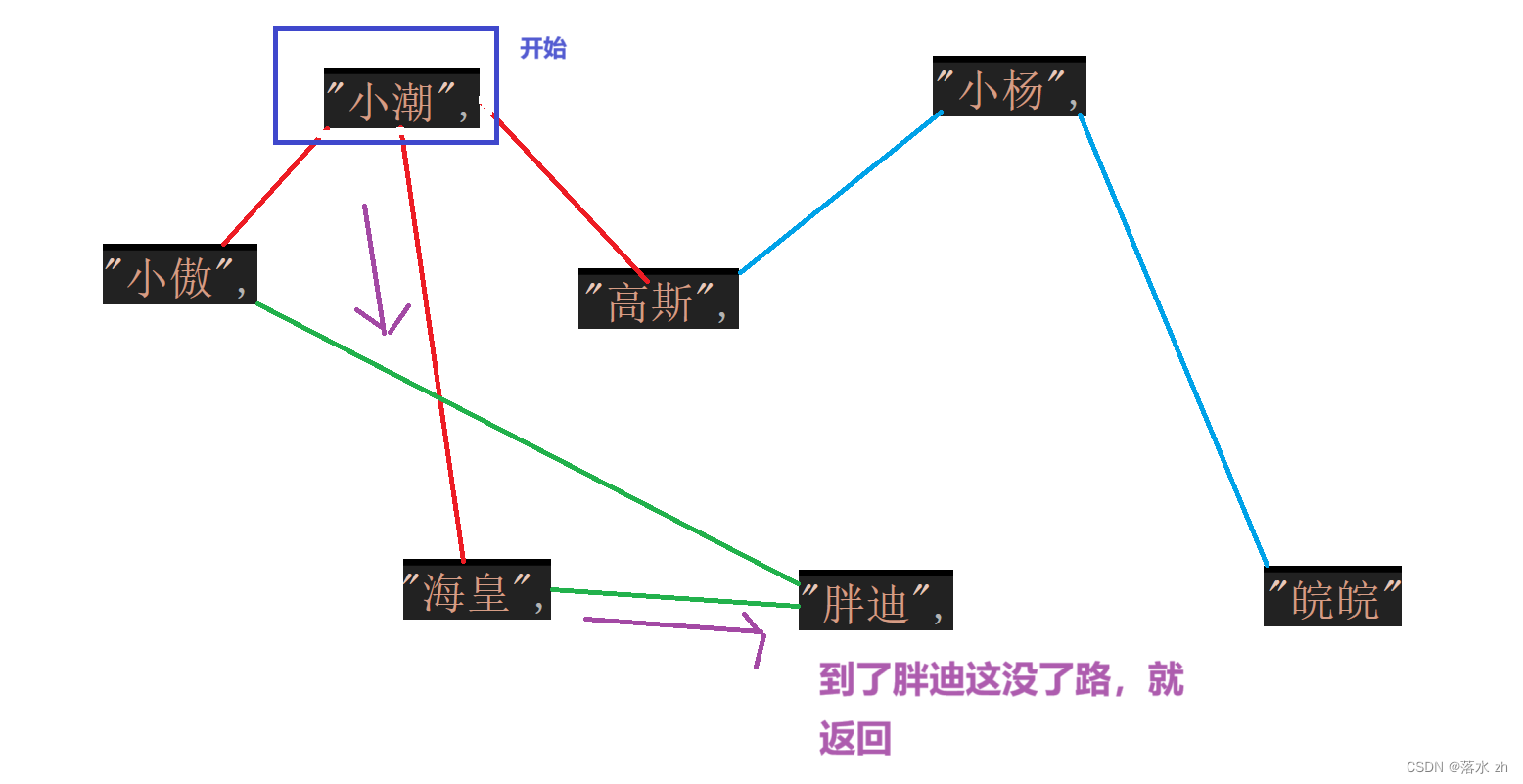
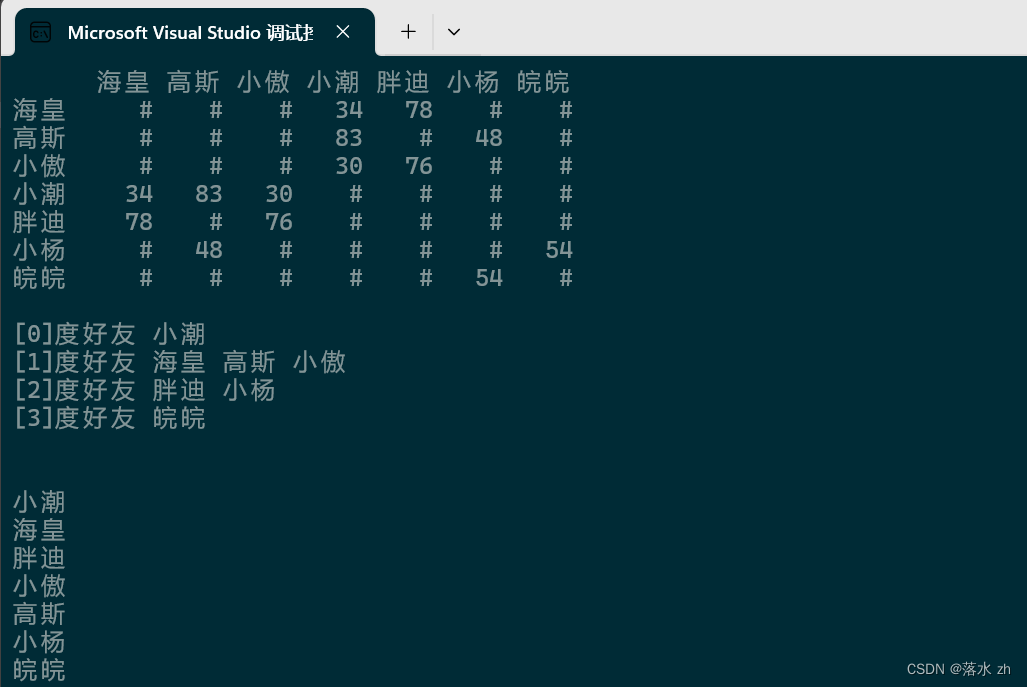
// 深度优先搜索的私有辅助函数
void _DFS(size_t vertexIndex, vector<bool>& visited)
{
// 如果当前顶点尚未访问过
if (!visited[vertexIndex])
{
// 输出当前顶点的值
cout << _vertex[vertexIndex] << endl;
// 将当前顶点标记为已访问
visited[vertexIndex] = true;
// 遍历所有顶点
for (size_t i = 0; i < _vertex.size(); i++)
{
// 如果当前顶点和遍历到的下一个顶点之间存在边,
// 表示为权重不是最大可能权重(MAX_W),
// 则对下一个顶点进行深度优先搜索
if (_matrix[vertexIndex][i] != MAX_W)
_DFS(i, visited);
}
}
}
// 公开的深度优先搜索函数,从给定的顶点开始
void DFS(const V& vertex)
{
// 查找给定顶点在顶点列表中的索引
size_t vertexIndex = FindSrci(vertex);
// 初始化一个布尔向量来跟踪每个顶点是否已被访问
vector<bool> visited(_vertex.size(), false);
// 调用私有辅助函数进行深度优先搜索
_DFS(vertexIndex, visited);
}
(注:本人是小潮院长粉丝,该文章中举的例子不代表真实好友关系,无意挑拨小潮院长内部成员关系,如有冒犯,请不要打我…)