无锁编程与分布式编程那个更适合多核
CPU
?
前一篇文章
多核系统中三种典型锁竞争的加速比分析讲过了三种典型锁竞争情况下的加速比情况,特别是分布式锁竞争的加速比和CPU核数成正比,有很好的加速比性能。由于近些年在学术界中,无锁编程属于研究热点。那么使用无锁编程是不是可以取得更好的加速比性能呢?或者说无锁编程是不是更适合多核CPU系统呢?
无锁编程主要是使用原子操作替代锁来实现对共享资源的访问保护,举个例子,要对某个整数变量进行加1操作的话,用锁保护操作的代码如下:
int a = 0;
Lock();
a+= 1;
Unlock();
如果对上述代码反编译可以发现 a+=1;被翻译成了以下三条汇编指令:
mov eax,dword ptr [a]
add eax,1
mov dword ptr [a],eax
如果在单核系统中,由于在上述三条指令的任何一条执行完后都可能发生任务切换,比如执行完第1条指令后就发生了任务切换,这时如果有其他任务来对a进行操作的话,当任务切换回来后,将继续对a进行操作,很可能出现不可预测的结果,因此上述三条指令必须使用锁来保护,以使这段时间内其他任务无法对a进行操作。
需要注意的是,在多核系统中,因为多个CPU核在物理上是并行的,可能发生同时写的现象;所以必须保证一个CPU核在对共享内存进行写操作时,其他CPU核不能写这块内存。因此在多核系统中和单核有区别,即使只有一条指令,也需要要加锁保护。
如果使用原子操作来实现上述加1操作的话,例如使用VC里的InterlockedIncrement来操作的话,那么对a的加1操作需要以下语句
InterlockedIncrement (&a);
这条语句最终的实际加1操作会被翻译成以下一条带lock前缀的汇编指令:
lock xadd dword ptr [ecx],eax
使用原子操作时,在进行实际的写操作时,使用了lock指令,这样就可以阻止其他任务写这块内存,避免出现数据竞争现象。原子操作速度比锁快,一般要快一倍以上。
使用lock前缀的指令实际上在系统中是使用了内存栅障(memory barrier),当原子操作在进行时,其他任务都不能对内存操作,会影响其他任务的执行。因此这种原子操作实际上属于一种激烈竞争的锁,不过由于它的操作时间很快,因此可以看成是一种极细粒度锁。
在无锁(Lock-free)编程环境中,主要使用的原子操作为CAS(Compare and Swap)操作,在VC里对应的操作为
InterlockedCompareExchange
或者
InterlockedCompareExchangeAcquire;
如果是
64
位的操作,需要使用
InterlockedCompareExchange64
或者
InterlockedCompareExchangeAcquire64
。使用这种原子操作替代锁的最大的一个好处是它是非阻塞的。
按照微软
MSDN
的说明,
InterlockedCompareExchange
带有全局的内存栅障
(full memory barrier)
,在使用了
full memory barrier
的情况下,即使不是访问同一内存变量的原子操作也会发生竞争,从竞争形式上来讲,会发生固定式锁竞争或随机锁竞争现象,并且无法实现分布式锁竞争的竞争模式,比起使用普通锁的竞争会更激烈,因此最终得到的加速比会比上一篇文章里讲的固定式锁竞争还要糟糕。
对于象
InterlockedCompareExchangeAcquire
这类的原子操作,没有使用
full memory barrier
,因此性能理论上会比使用
full memory barrier
的原子操作好很多(由于目前这类原子操作只有在特定的机器才支持,具体性能到底如何没有测试过,微软的
MSDN
里也对性能方面作出说明)。但是如果采用固定式锁竞争形式,其加速比仍然是按照前面的固定式锁竞争的加速比公式来计算:
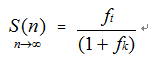
由于原子操作速度比锁快,其实相比于普通锁操作,相当于加锁解锁时间
鈥?鈥濆簲鐢ㄧ▼搴忎腑鐨勬湇鍔″櫒閿欒銆?hr width=100% size=1 color=silver>
鍙傛暟鏃犳晥銆?/i>
璇存槑: 鎵ц褰撳墠 Web 璇锋眰鏈熼棿锛屽嚭鐜版湭澶勭悊鐨勫紓甯搞€傝妫€鏌ュ爢鏍堣窡韪俊鎭紝浠ヤ簡瑙f湁鍏宠閿欒浠ュ強浠g爜涓鑷撮敊璇殑鍑哄鐨勮缁嗕俊鎭€? 寮傚父璇︾粏淇℃伅: System.ArgumentException: 鍙傛暟鏃犳晥銆?br>
婧愰敊璇?
鍙湁鍦ㄨ皟璇曟ā寮忎笅杩涜缂栬瘧鏃讹紝鐢熸垚姝ゆ湭澶勭悊寮傚父鐨勬簮浠g爜鎵嶄細鏄剧ず鍑烘潵銆傝嫢瑕佸惎鐢ㄦ鍔熻兘锛岃鎵ц浠ヤ笅姝ラ涔嬩竴锛岀劧鍚庤姹?URL: |
鍫嗘爤璺熻釜:
|
鐗堟湰淇℃伅: Microsoft .NET Framework 鐗堟湰:2.0.50727.832; ASP.NET 鐗堟湰:2.0.50727.832

